- Published on
深入浅出React和Redux
- Authors

- Name
- 三金得鑫
- 掘金
- 掘金
目录
- React 相较于原生的优缺点
- CRA 中的 eject
- React 的理念
- Virtual DOM
- React 工作方式的优点
- 组件的设计要求
- React 组件的数据
- prop
- state
- 两者对比
- 两者的局限
- 组件的生命周期
- Flux
- MVC 框架的缺陷
- Flux 应用
- 1. Dispatcher
- 2. Action
- 3. Store
- 4. View
- Flux 的优势
- 不足
- 1. Store 之间依赖关系
- 2. 难以进行服务端渲染
- 3. Store 混杂了逻辑和状态
- Redux
- 1. 唯一数据源
- 2. 保持状态只读
- 3. 数据改变只能通过纯函数完成
- Redux 实例
- 容器组件和傻瓜组件
- 组件 Context
- React-Redux
- connect
- Provider
- 模块化应用要点
- 代码文件的组织结构
- 1.按角色组织
- 2.按功能组织
- 模块接口
- 状态树的设计
- 1. 一个状态节点只属于一个模块
- 2. 避免冗余数据
- 3. 树形结构扁平
- 组合 Reducer
- View 视图开发注意点
- React 组件的性能优化
- 1. 节点类型不同的情况
- 2. 节点类型相同的情况
- Key 的用法
- 使用 reselect 提高数据获取性能
- 范式化状态树
- 高阶组件
- 代理方式的高阶组件
- 继承方式的高阶组件
- 以函数为子组件
- 代理访问 API
- Redux 中间件
- Redux 和服务器通信
- 单元测试
- 测试种类
- 测试框架
- 测试代码组织
- 动画
- CSS3方式
- 脚本方式
- 同构
- React 服务器端渲染 HTML
- End
这本书是今年看完的第二本书,里面的技术栈虽然有些过时,但是讲解设计原理的部分永不过时,给人眼前一亮,之前的一些比较模糊的点,也清晰了起来。
React 相较于原生的优缺点
React 的首要思想是通过组件-Component 来开发应用。
组件,说白了就是高度封装的一个方法,在前端框架中,这个方法最终经过解析器解析返回一个虚拟DOM。
通过组件,用分而治之的方式,把一个大的应用分解成若干小的组件,每个组件只关注某个小范围的特定功能(这里我们遵循的是单一职责原则),但是把组件组合起来,就能构成一个功能庞大的应用。
想象一下,组件在现实世界就是积木、乐高,我们可以通过组合拼装把他们搭建成一个完整的物品
在使用 React 创建组件时,有一点必须注意:在 JSX 代码文件中,即使代码中没有直接使用 React,也一定要导入这个 React,这是因为 JSX 最终会被转译成依赖于 React 的表达式。
那么什么是 JSX 呢?
所谓 JSX,是 JS 的语法扩展,让我们在 JS 中可以编写像 HTML 一样的代码。它有以下几个特点:
- 首先,在 JSX 中使用的元素不局限于 HTML 中的元素,可以是任何一个 React 组件。React 判断一个元素是 HTML 元素还是一个组件的原则就是看第一个字母是否大写;
- 其次,在 JSX 中可以通过 onClick 这样的方式给一个元素添加一个事件处理函数(这不同于原生中的
onclick,直接在 HTML 上添加事件会带来代码混乱的问题,所以后来 JQuery 应运而生了);
那么,在 JSX 中使用 onClick 添加事件处理函数和原生的事件处理函数具体的不同点在哪里呢?
我们先来看看原生的事件处理函数,以 onclick 为例:
onclick添加的事件处理函数是在全局环境下执行的,这污染了全局环境,很容易产生意料不到的后果;- 给很多 DOM 元素添加
onclick事件,可能会影响网页的性能,要知道网页需要的事件处理函数越多,性能就会越低; - 对于使用
onclick的DOM元素,如果要动态地从 DOM 树中删除的话,需要把对应的时间处理器注销(也就是定时器),如果忘记注销,就可能造成内存泄漏,这个的问题是很难发现的(毕竟不报错)
而这些问题,在 JSX 中就不会存在。
首先,onClick 挂载的函数,都被控制在组件范围内,是不会污染全局空间的。
我们在 JSX 中看到的 onClick,实际并没有像原生那样直接和 HTML 绑定到一起,而是使用了事件委托的方式处理点击事件,无论有多少个 onClick 出现,其实最后都只在 DOM 树上添加了一个事件处理函数,挂在最顶层的 DOM 节点上。所有的点击事件都被这个事件处理函数捕获,然后分发给特定的函数,使用事件委托的性能当然要比为每个 onClick 都挂载一个事件处理函数要高。
因为 React 控制了组件的生命周期,在 unmount 的时候自然能够清除相关的所有事件处理函数,内存泄漏也不再是一个问题。
那么对于 JSX 来说,它是一种进步还是一种倒退呢?
根据做同一件事的代码应该具有高耦合性的设计原则,我们在设计一个功能时,比较合理的方式就是把实现这个功能的代码都集中到一个文件里,也就是这样:
之前用 HTML 代表内容,用 CSS 代表样式,用 JavaScript 来定义交互行为,实际上是把不同技术分开管理,而不是逻辑上的“分而治之”。
而 React 组件则是把 JS、HTML 和 CSS 的功能都封装在一个文件中,这实现了真正意义上的组件封装。
CRA 中的 eject
当我们使用 CRA 来创建一个 React 项目时,脚手架会为我们提供一个 eject 弹射脚本命令,它的作用是把潜藏在 react-scripts 中的一系列技术栈配置都释放到应用的顶层,然后我们就可以研究这些配置细节,并灵活地定制应用的配置。
eject命令是不可逆的,毕竟没有一个从战斗机中弹射出去的飞行员能再飞回驾驶舱一样。
执行弹射后,当前根目录下会增加两个目录:
scriptsconfig
与此同时,package.json 文件中的 scripts 部分也发生了变化:
{
"scripts": {
"start": "node scripts/start.js",
"build": "node scripts/build.js",
"test": "node scripts/test.js --env=jsdom"
}
}
至此,弹射结束,再也回不去了。
React 的理念
我们对比 JQuery和 React:
假设 React 是一个聪明的建筑工人,而 JQuery 是一个比较愚笨的建筑工人,而开发者本身是一个建筑设计师,这两个位建筑工人的工作方式如下:
- JQuery:需要你事无巨细地告诉他如何去做。简单的来说,使用 JQuery 就需要我们一步一步进行指导操作,获取什么节点,执行什么动作;
- React:你只需要告诉他你想要什么,即只需要一张图纸,他就能替你搞定一切,他不会把整个建筑都重新拆掉,而是将原来的图纸和现在的图纸做对比,只修改不同的地方。它支持差异化增量修改,并不会牵一发而动全身。
显而易见,React 的工作方式就是把开发者从繁琐的操作中解放出来,我们只需要关心我想要显示什么,而不用操心怎样去做。
React 的理念,归结为一个公式:UI=render(data)。
即用户看到的界面(UI),应该是一个 render 函数的执行结果,它只接受数据 data 的参数。且这个函数是一个纯函数。
纯函数指的是没有任何副作用,输出完全依赖于输入的函数,两次函数调用如果输入相同,得到的结果也绝对相同。
Virtual DOM
这是当下流行响应式框架中避不开的一个话题——虚拟 DOM。
要了解虚拟DOM,我们需要先了解真实DOM。DOM 是结构化文本的抽象表达形式,特定于 Web 环境中,而结构化文本的实际展示就是 HTML 文本,HTML 中的每个元素都对应 DOM 中的某个节点,这样,因为 HTML 元素的逐级包含关系,DOM 节点自然就构成一个属性结构,称为 DOM 树。
而浏览器为了渲染 HTML 格式的网页,就先将 HTML 文本解析以构建出 DOM 树,然后根据 DOM 树渲染出用户看到的界面,当要改变界面内容的时候,就去改变 DOM 树上的节点。(PS:这也是浏览器渲染机制的一部分)
但是传统的 DOM 操作,会直接改变 DOM 节点,从而可能引发回流和重绘,影响性能。因为虽然浏览器是多线程的,但是 JS 线程和UI线程是共用一个线程,这个线程也被称为主线程,而在主线程中,它俩的执行时冲突的,且页面渲染的耗时远远大于 JS 代码的执行。所以应该尽量减少页面的重新渲染,来提升整体性能。
知道了 DOM 之后,我们在回过头看看虚拟DOM。
既然 DOM 树是对 HTML 的抽象,那么虚拟DOM就是对DOM树的抽象。
虚拟DOM不会触及浏览器的部分,只是存在于JS空间的树形结构,每次自上而下渲染 React 组件时,会对比这次和上次的虚拟DOM,找出两者的不同点,从而修改两次之间的差异部分即可。这涉及到DIFF算法,之后会有专门的部分进行学习探讨。
React 工作方式的优点
同样的,我们以 JQuery 为例。
使用 JQuery 进行开发,项目越大,代码维护越困难,最终会让它的工作方式变得如下图所示:
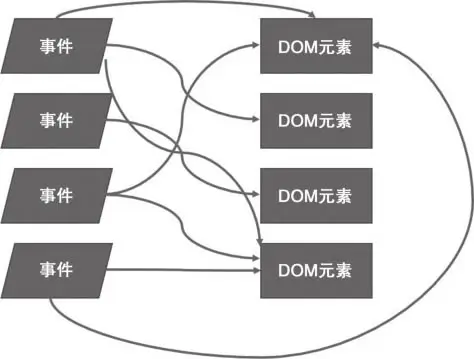
而使用 React 则不会出现这样的问题。因为无论何种事件,引发的都是 React 组件的重新渲染,至于如何只修改必要的 DOM 部分,则完全交给 React 去操作即可,开发者无需关心。
这里涉及到一个概念——关注点分离。
关注点分离在计算机科学中,是将代码分割为不同部分的设计原则,是面向对象的程序设计的核心概念。其中每一部分会有各自的关注焦点
在 React 中最终程序的流程简化为如下图所示:
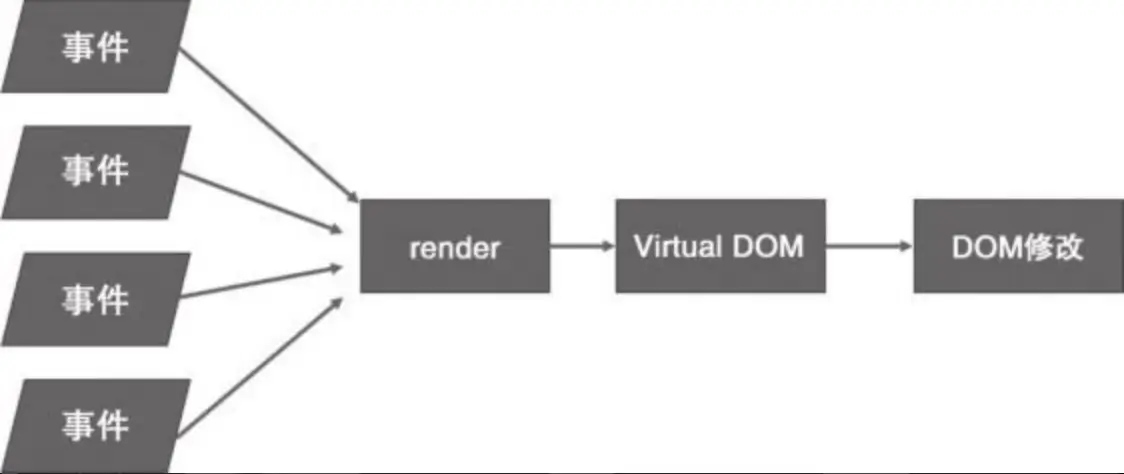
React 利用函数式编程的思维来解决用户界面渲染的问题,最大的优势是开发者的效率会大大提高,且开发出的代码可维护性和可阅读性也大大增强。
按照由数据驱动渲染的工作模式,可让程序处于可控范围内。
组件的设计要求
一个组件只做一件事,即要符合单一职责原则,让组件本身易于排错和维护管理。
那么如何具体地进行组件的设计和开发呢?——关键点就是确定组件的边界。
每个组件都应该是可以独立存在的,如果两个组件逻辑太紧密,耦合度很高,无法清晰定义各自的责任,那这两个组件或许就不应该被拆开,让其作为一个组件可能会更加合理。
其实这里也涉及到了设计原则中的面相接口编程的思想。
简单点来说就是开发者把具体实现对外隐藏,只透出必要的接口给使用者。
而作为软件设计的通用原则,组件的划分也需要满足高内聚和低耦合。
这里又说到了两个在编程领域中老生常谈的两个概念:
- 高内聚:把逻辑紧密相关的内容放在一个模块中,只暴露出必要的 API 和返回确定的结果,对外界依赖少甚至不依赖;
- 低耦合:多个模块之间的联系仅限于简单的接口,没有强关联功能和依赖,可以拆开功能和作用分别用于其他逻辑,相互独立不影响;
React 组件的数据
差劲的程序员操心代码,优秀的程序员操心数据结构和它们之间的关系——Linus Torvald, Linux 创始人
编程核心的东西还是数据结构和算法,有些书本里是这样描述程序的:程序=数据结构+算法。越是高级的程序员,越需要更加抽象的思维能力,越需要看清程序的本质,而不是拘泥于程序代码的具体实现上。这也是业内流传最顶级的程序员都是数学家的原因,因为他们的抽象能力无与伦比。
React 组件的数据可以分为两种:
- 自身状态(可控)——state
- 对外接口(不可控)——prop
这里的可控和不可控都是基于自身而言的,后面会有讲。
prop
在 React 中,prop是从外部传递给组件的数据,一个组件通过定义自己能够接受的 prop,就定义了自己的对外公共接口。
使用 prop 可以实现 React 父子组件之间的通信:
- 父传子:父组件向子组件传入 prop
- 子传父:子组件通过父组件传进来的函数类型的 prop,把组件内部的信息传给父级
上面有说到 prop 可以是函数类型,那同样的,prop 也可以是其他类型。在 ES6 以后的组件中,可以通过增加类(构造函数)的 propTypes 属性来定义 prop 的规格限制,在运行时和静态代码检查时,都可以根据 propTypes 判断外部环境是否正确使用了组件的属性。而要使用 propTypes 就不得不使用一款插件 prop-types,这是 React 开发中必不可少的一款限制属性类型的插件。
state
state 代表组件的内部状态。由于组件自身是不能修改传入的 prop(单向数据流),所以需要记录自身数据变化,就要使用 state。
在 React 组件中,是不能直接修改 state 的值的,这里需要使用官方提供的 setState 方法,它所做的事情:首先是改变 state 的值,然后驱动组件发生更新,这样才能让 state 的新值出现在界面上。
两者对比
- prop 用于定义外部接口,state 用于记录内部状态
- prop 的赋值是在外部环境使用组件时,而 state 的赋值时在组件内部
- 组件不应该改变 prop 的值,而 state 存在的目的就是让组件来改变的
- prop 是一个或多个子组件共享的属性,权限为只读,而 state 是每个子组件独有的,权限为读写
- 某个数据选择使用 prop 还是用 state 表示,最终取决于这个数据时对外还是对内
组件的 state,就相当于组件的记忆
我们回过头看之前提到的公式:UI=render(data)。
React 组件扮演的是 render 函数的角色,应该是一个没有副作用的纯函数。而修改 props 的值,是一个副作用,组件应该避免。
两者的局限
- 父子组件需要维护同一份数据,会导致数据重复
- props 传递,需要经历中间所有层
- state 的冗余重复,容易导致数据的不一致;prop 的跨级传递,违背低耦合原则
我们这里需要保证数据的一致性。如果数据出现重复,带来的一个问题就是如何保证重复的数据一致,如果数据存多份而且不一致,那就很难决定到底使用哪个数据作为正确结果了。
假如有如下图一样的结构时,要如何解决呢?
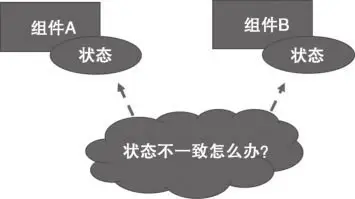
一个直观的解决方法就是以某一个组件的状态为准,使其成为顶层状态,其余状态都保持和它一致。但是实际上这种方法很难实现,且在一些复杂场景下会带来很大的心智负担,比如多个组件状态都会影响到一个组件时,那对于这个组件来说就会有多个顶层状态,这在设计上来讲也是不合理的。
还有一种思路就是将这个状态直接放在全局,然后哪些组件需要使用该状态,直接引用。让这个全局状态成为唯一可靠的数据源。
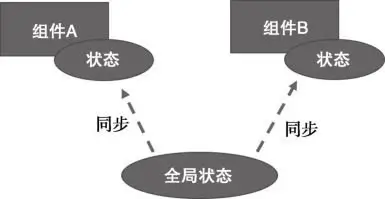
组件的生命周期
React 严格定义了组件的生命周期,生命周期可能会经历如下三个过程:
- 装载过程(Mount):把组件第一次在 DOM 树中渲染的过程
- 更新过程(Update):当组件被重新渲染的过程
- 卸载过程(Unmount):组件从 DOM 中删除的过程
在这里我们需要知道 render 函数它不做实际渲染的动作,它只是返回一个 JSX 描述的结构,最终由 React 来操作渲染过程。而这里就是由 React.createElement API 将其转化为 element,再通过私有类 mountComponent将 element 转成真实 DOM 节点,并且插入到相应的 container 里,然后返回 markup(real DOM)。
Flux
上面我们已经感受到了完全使用 React 来管理应用数据的麻烦,也提出了一些想法,其中引出了将状态提到全局的设计方案。Flux 就是这样的一个状态管理框架,也是单向数据流框架的始祖。
说到状态库,这里我们不得不提一下之前一直称霸于编程领域的框架模式——MVC。
MVC 框架的缺陷
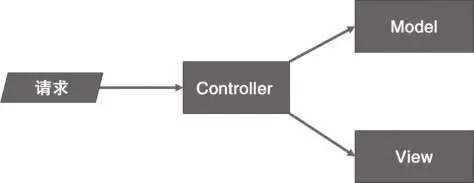
MVC 框架是业界广泛接受的一种前端应用框架类型,这种框架把应用分为三个部分:
- Model(模型):负责管理数据,大部分业务逻辑也应该在 Model 中
- View(视图):负责渲染用户界面,应该避免在 View 中涉及业务逻辑
- Controller(控制器):负责接受用户输入,根据用户输入调用对应的 Model 部分逻辑,把产生的数据结果交给 View 部分,让 View 渲染出必要的输出
MVC 框架的几个组成部分和请求的关系如图:
这样的逻辑划分,实质上与把以一个应用划分为多个组件一样,就是分而治之。
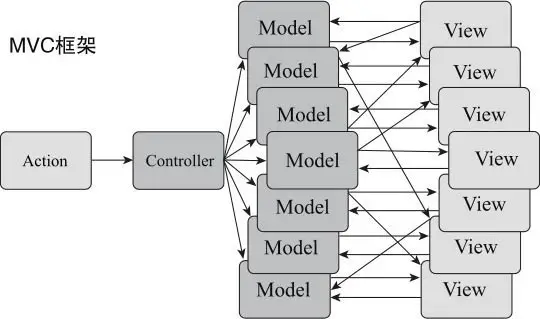
MVC 框架提出的数据流很理想:
- 用户请求先到 Controller
- 然后由 Controller 调用 Model 获得数据
- 最后把数据交给 View
但是实际呢?开发过程中总是允许 View 和 Model 可以直接进行通信,从而导致 View 和 Model 之间的关系像蜘蛛网一样复杂。
而后 Facebook 为了能更好的管理数据流,推出了 Flux,它从设计上将数据流控制得更加严格,不再像 MVC 一样,它的特点是——单向数据流。如下图是 Flux 框架大致的结构:
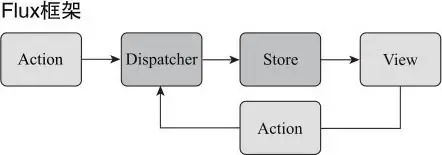
一个 Flux 应用包含四个部分:
- Dispatcher:处理动作分发,维持 Store 之间的依赖关系
- Store:负责存储数据和处理数据相关逻辑
- Action:驱动 Dispatcher 的 JS 对象
- View:视图部分,负责显示用户界面
如果需要把 Flux 和 MVC 做一个结构对比,那么:
- Dispatcher 相当于 Controller
- Store 相当于 Model
- View 等于 View
- Action,可以理解为对应给 MVC 框架的用户请求
当需要扩充应用所能处理的请求时,MVC 方法就是新增新的 Controller,而对于 Flux 则只是增加新的 Action。
Flux 应用
我们说一个 Flux 应用由四部分组成,那么我们围绕这四部分,来创建一个应用看看。
先进行下载安装:npm install --save flux。
1. Dispatcher
我们需要知道的是,几乎所有应用都只需要拥有一个 Dispatcher。所以首先要做的是创建一个 dispatcher.js 文件:
import { Dispatcher } from 'flux';
export default new Dispatcher();
Dispatcher 存在的作用,就是用来派发 Action。
2. Action
Action 顾名思义代表一个动作,不过这个动作只是一个普通的 JS 对象,代表一个动作的纯数据。
作为管理,Action 对象必须有一个名为 type 的字段,代表这个 Action 对象的类型,为了记录日志和 debug 方便,这个 type 应该是字符串类型。
通常定义 Action 需要两个文件,一个定义 Action 类型,一个定义 Action 的构造函数(也就是 Action Creator)。而分成两个文件的主要原因是在 Store 中会根据 Action 类型做不同的操作,也就有单独导入 Action 类型的需要。
比如我们先创建一个 ActionTypes.js 用来定义 Action 的类型:
export const INCREMENT = 'increment';
export const DECREMENT = 'decrement';
然后新建我们的 ActionCreator文件——Ations.js:
import * as ActionTypes from './ActionTypes.js' ;
import AppDispatcher from './dispatcher.js';
export const increment = (counterCaption) => {
AppDispatcher.dispatch({
type: ActionTypes.INCREMENT,
counterCaption,
})
}
export const decrement = (counterCaption) => {
AppDispatcher.dispatch({
type: ActionTypes.DECREMENT,
counterCaption,
})
}
⚠️注意:里面定义的并不是 Action 对象本身,而是能够产生并派发 Action 对象的函数。
3. Store
一个 Store 也是一个对象,这个对象存储应用状态,同时还要接受 Dispatcher 派发的动作,根据动作来决定是否要更新应用状态。
在我们的应用中,做出相应的部分应该是 View 部分,但是我们并不应该硬编码这种联系,而是用消息的方式建立 Store 和 View 的联系。而为了建立这种联系,我们为 Store 扩展 EventEmitter.prototype,也就是说让 Store 变成了一个 EventEmitter 对象。
一个 EventEmitter 实例对象支持下列相关的函数:
- emit 函数:可以广播一个特定事件,第一个参数是字符串类型的事件名称
- on 函数:可以增加一个挂在这个 EventEmitter 对象特定事件上的处理函数,第一个参数是字符串类型的事件名称,第二个参数是处理函数
- removeListener 函数:和 on 函数做的事情相反,它主要是删除挂在这个 EventEmitter 对象特定事件上的处理函数
const counterValues = {
'First': 0,
'Second': 10,
'Third': 30
};
const CounterStore = Object.assign({}, EventEmitter.prototype, {
getCounterValues: function() {
return counterValues;
},
emitChange: function() {
this.emit(CHANGE_EVENT)
},
addChangeListener: function() {
this.on(CHANGE_EVENT, callback)
},
removeChangeListener: function() {
this.removeListener(CHANGE_EVENT, callback)
},
})
对于 Store 来说,并不是必须要存储什么东西,Store 只是提供获取数据的方法,而 Store 提供的数据完全可以由另一个 Store 计算得来。
当一个动作被派发时,Dispather 就是简单地把所有注册的回调函数都全部调用一遍,至于这个动作是不是对方关心的,Flux 的 Dispatcher 不关心,要求每个回调函数去鉴别。这看起来似乎是一种浪费,但是这个设计让 Flux 的 Dispatcher 逻辑简单化,责任越简单,越不容易出问题。
4. View
存在于 Flux 框架中的 React 组件需要实现以下几个功能:
- 创建时要读取 Store 上的状态来初始化组件内部状态
- 当 Store 上状态发生变化时,组件要立刻同步更新内部状态保持一致
- View 如果要改变 Store 状态,必须而且只能派发 Action
Flux 的优势
在 Flux 的架构下,应用的状态被放在 Store 中,React 组件只是扮演 View 的作用,被动根据 Store 的状态来渲染。
在 Flux 中,用户的操作会引发一个动作的派发,这个派发的动作会发送给所有的 Store 对象,引发了 Store 对象的状态改变,而不是直接引发组件的状态改变。因为组件的状态是 Store 状态的映射,所以改变了 Store 对象也就触发了组件对象的状态改变,从而引发了界面的重新渲染。
Flux 带来了哪些好处呢?最重要的就是单向数据流的管理方式。
在 Flux 的理念里,如果要改变界面,必须改变 Store 中的状态,如果要改变 Store 中的状态,必须派发一个 Action 对象,这是必须遵循的一个规则。
不足
1. Store 之间依赖关系
在 Flux 的体系中,如果两个 Store 之间有逻辑依赖关系,就需要使用 Dispatcher 的 waitFor 函数。而我们说最好的依赖管理是根本不让依赖产生。
2. 难以进行服务端渲染
我们需要知道的是,如果要在服务端进行渲染,输出的不是一个 DOM 树,而是一个字符串,准确来说就是一个全是 HTML 的字符串。
在 Flux 体系中,有一个全局的 Dispatcher,然后每一个 Store 都是一个全局唯一的对象,这对于浏览器来说完全OK,但是如果在服务端就是一个大问题。因为服务端要同时接受很多用户的请求,如果每个 Store 都是全局唯一的对象,那不同请求的状态肯定就乱套了。
简单来说,一个用户对应一个状态 Store,而在服务端需要对每个用户的 Store 都需要进行管理。
3. Store 混杂了逻辑和状态
因为 Store 的设计是要封装数据和处理数据的逻辑,而假如我们需要动态替换一个 Store 的逻辑时,只能将整个 Store 都给替换掉,这会导致无法保持已经存储到 Store 里的状态。
Redux
在 Flux 饱受争议的时候,Redux 出生了,它是基于 Flux 改进的状态管理框架。遵循以下四个基本原则:
- 单向数据流
- 唯一数据源
- 保持状态只读
- 数据改变只能通过纯函数完成
我们主要看看后面三点。
1. 唯一数据源
即应用的状态数据应该只存储在唯一的一个 Store 上。整个 Store 是一个状态树,组件一般只使用部分,如何创建合理的 Store 树形结构很关键。
2. 保持状态只读
保持状态只读,意思就是不能直接去修改状态,要修改 Store 的状态,必须要通过派发一个 Action 对象来完成。这个对象会返回给 Redux,由 Redux 完成新的状态组装。
3. 数据改变只能通过纯函数完成
这里说的纯函数就是 Reducer,它不是 Redux 特定的术语,而是一个计算机科学中的通用概念,很多语言和框架都有对 Reducer 函数的支持。JS 中,数组就有 reduce函数:遍历一个数组,对每一个元素执行相同的操作,同时让上一次的执行结果作为下一次的输入,输出给下下次。
在 Redux 中修改 Store 的状态必须通过 Reducer:reducer(state, action),这是基本格式,state 是要修改的状态,action 是 reducer 接收到的 action 对象,reducer 就是要根据 state 和 action 来产生一个新的对象。
对于 Redux 来说,Reducer 只负责计算状态,不负责存储状态。
在计算机编程的世界里,完成任何一件任务,可能都有一百种以上的方法,但是无节制的灵活度反而让软件难以维护,增加限制是提高软件质量的法门。
Redux 实例
和 Flux 一样,Redux 应用习惯上也把 action 类型和 action 构造函数分成两个文件定义。其中类型文件和 Flux 并无差别,但是 Actions.js 文件就大不一样了。
import * as ActionTypes from './ActionTypes.js';
export const increment = (counterCaption) => {
return {
type: ActionTypes.INCREMENT,
counterCaption,
}
}
export const decrement = (counterCaption) => {
return {
type: ActionTypes.DECREMENT,
counterCaption,
}
}
它们的不同点在于 Redux 中每个 action 构造函数都返回一个 action 对象,而 Flux 版本中 action 构造函数并不返回什么,而是把构造函数的动作函数立刻通过调用 Dispatcher 的 dispatch 函数派发出去。
在 Redux 中,派发动作是由 Store 对象上的 dispatch 函数执行的,并不像 Flux 里还需要创建一个 Dispatcher 对象。
我们创建一个 Store.js 文件,这个文件输出全局唯一的那个 Store,代码如下:
import { createStore } from 'redux';
import reducer from './Reducer.js';
const initValues = {
'First': 0,
'Second': 10,
'Third': 20
}
const store = createStore(reducer, initValues);
export default store;
我们这里使用 Redux 库提供的 createStore 函数,创建了一个 store 实例。
确定 Store 状态,是设计好 Redux 应用的关键。我们必须遵循 Redux 唯一数据源的基本原则。且需要遵循避免冗余数据的设计原则。
容器组件和傻瓜组件
我们先来了解一下相关的概念:
- 容器组件:负责和 Redux Store 打交道的组件,处于外层;
- 傻瓜组件(展示组件):专心负责渲染界面的组件,处于内层;它就是一个纯函数,根据 props 产生结果。

让一个组件只专注做一件事,如果发现一个组件做的事情太多了,就可以把这个组件拆分成多个组件,让每个组件依然只专注做一件事。
其实这里也就是我们常说的有状态组件和无状态组件。而这里有一点也需要注意,那就是拆分容器组件和傻瓜组件,是设计 React 组件的一种模式,和 Redux 没有直接关系。
组件 Context
有一个场景:设想在一个嵌套多层的组件结构中,只有最里层的组件才需要使用 Store,但是为了把 Store 从最外层传递到最里层,就要求中间所有的组件都需要增加对这个 Store Prop 的支持,即使根本不使用它,这无疑很麻烦。
React 提供了一个叫 Context 的功能,可以完美的解决这个问题。
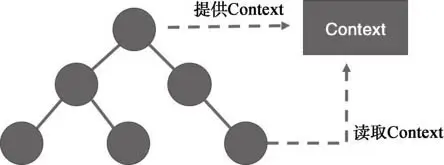
所谓 Context,就是上下文环境,让一个树状组件上所有组件都能访问一个共同的对象,为了完成这个任务,需要上级组件和下级组件配合。
- 首先上级组件要宣称自己支持 context,并且提供一个函数来返回代表 Context 的对象;
- 然后,这个商机组件之下的所有子孙组件,只要宣称自己需要这个 context,就可以使用
useContexthook 访问到这个共同的环境对象
那么我们如何把 context 提供给顶层组件呢?这里还需要创建一个特殊的 React 组件——Provider。它的作用将是一个通用的 context 提供者,可以应用在任何一个应用中。
import { PropTypes, Component } from 'react';
class Provider extends Component {
getChildContext() {
return {
store: this.props.store
}
}
render() {
return this.props.children;
}
}
Provider.childContextTypes = {
store: PropTypes.object
}
可以看到 Provider 组件的作用很单纯,就是简单地把子组件渲染出来,在渲染上,Provider 不做任何附加的事情。而为了让 Provider 能够被 React 认可为一个 Context 的提供者,还需要指定 Provider 的 childContextTypes 的属性。只有定义了类的 childContextTypes,和类里的 getChildContext 方法相对应,Provider 的子组件才有可能访问到 context。
这是在类组件中需要注意的,不过现在大都是函数组件,我们需要重新学习了解 hooks
useContext相关的知识了。
就单纯来看 React 的 Context 功能的话,必须强调这个功能要谨慎使用,只有对那些每个组件都可能使用,但是中间组件又可能不使用的对象才有必要使用 Context,千万不要滥用。
React-Redux
在之前的学习中,我们了解了改进 React 应用的两个方法。
- 第一是把一个组件拆分为容器组件和傻瓜组件
- 第二是使用 React 的 Context 来提供一个所有组件都可以直接访问的 Context
不难发现的是,这两种方法都有套路,完全可以把套路部分抽取出来复用,这样每个组件的开发就只需要关注于不同的部分就可以了。
实际上,已经有这样的一个库来完成这些工作了,这个库就是 react-redux。它有两个主要的功能:
- connect:连接容器组件和傻瓜组件
- Provider:提供包含 store 的 context
connect
export default connect(mapStateToProps, mapDispatchToProps)(Component);
实际上 connect 是一个高阶函数,它接收两个参数:mapStateToProps和 mapDispatchToProps,执行结果依然是一个函数,而这个函数接收一个组件作为其参数,最终返回一个容器组件。
那 connect 函数具体做了什么工作呢?
作为容器组件,要做的工作无外乎两件事:
- 把 Store 上的状态转化为内层傻瓜组件的 prop;
- 把内层傻瓜组件的用户动作转化为派送给 Store 的工作。
把内层傻瓜组件中用户动作转化为派送给 Store 的动作,也就是内层傻瓜组件暴露出来的函数类型的 prop 关联上 dispatch 函数的调用,每个 prop 代表的回调函数的主要区别就是 dispatch 函数的参数不同,这就是 mapDispatchToProps要做的事情。
Provider
在 React-Redux 中,Provider 和我们之前的例子几乎一样,但是更加严谨,比如要求 Store 不光是一个对象,而且是必须包含三个函数的对象,分别是:
- subscribe
- dispatch
- getState
模块化应用要点
React 适合视图层面的东西,但是不能指望靠 React 来管理应用的状态,Redux 才适合担当应用状态的管理工作。
从架构出发,当我们开始一个新的应用的时候,有几件事是一定要考虑清楚的:
- 代码文件的组织结构
- 确定模块的边界
- Store 的状态树设计
这三件事,是构建一个应用的基础。如果我们在一开始深入思考这三件事,并做出合乎需要的判断,可以在后面的路上省去很多麻烦。确定了我们的应用要做什么之后,不要上来就开始写代码,磨刀不误砍柴工,先要思考这三个问题才可以。
代码文件的组织结构
1.按角色组织
在 MVC 中,应用代码分为 Controller、Model 和 View,分别代表三种模块角色,就是把所有的 Controller 代码都放在 controllers 目录下,把所有的 Model 代码放在 models 目录下,把 View 代码放在 views 目录下。这种组织代码的方式,叫做按角色组织。
不过虽然按照角色组织的方式看起来不错,但是实际上非常不利于应用的扩展。比如当我们需要对一个功能进行修改的时候,虽然这个功能知识针对某一个具体的应用模块,但是却牵扯到 MVC 中的三个角色 Controller、Model 和 View,不管我们用的是什么编辑器,都得在这三个目录之间进行跳转,或者需要滚动文件列表跳过无关的分发器文件才能找到你想要修改的那一个分发器文件。这非常的浪费时间。
2.按功能组织
Redux 应用适合于按功能组织,也就是把完成同一应用的代码放在一个目录下,一个应用功能包含多个角色代码。
模块接口
在最理想的情况下,我们应该通过增加代码就能增加系统的功能,而不是通过对现有代码的修改来增加功能。——Robert C. Martin
我们再来回顾一下高内聚低耦合:
不同功能模块之间的依赖关系应该简单而且清晰,也就是所谓的保持模块之间低耦合;一个模块应该把自己的功能封装得很好,让外界不要太依赖与自己内部的结构,这样不会因为内部的变化而影响到外部模块的功能,这就是所谓的高内聚。
现在假如我们把一个目录看做是一个模块,那么我们要做的就是明确这个模块对外的接口是什么,而这个接口应该实现把内部封装起来。
状态树的设计
因为所有的状态都存在 Store 上,Store 的状态树设计,直接决定了要写哪些 reducer,还有 action 怎么写,所以是程序逻辑的源头。
我们认为状态树设计要遵循如下几个原则:
- 一个模块控制一个状态节点
- 避免冗余数据
- 树形结构扁平
1. 一个状态节点只属于一个模块
在 Redux 应用中,Store 上的每个 state 都只能通过 reducer 来更改,而我们每个模块都有机会到处一个自己的 reducer,这个导出的 reducer 只能最多更改 Redux 的状态树上一个节点下的数据,因为 reducer 之间对状态树上的修改权是互斥的,不可能让两个 reducer 都可以修改同一个状态树上的节点。
2. 避免冗余数据
传统的关系型数据库中,对数据结构的各种“范式化”,其实就是在去除数据的冗余。
范式化:用来改造关系模式,通过分解关系模式来消除其中不合适的数据依赖,以解决插入异常、删除异常、更新异常和数据冗余问题。
范式:构造数据库必须遵循一定的规则。在关系数据库中,这种规则就是范式。
不过对于 NoSQL 数据库来说,提倡的是在数据存储中“去范式化”,对数据结构的处理和关系型数据库正好相反,利用数据冗余来减少读取数据库时的数据关联工作。
3. 树形结构扁平
这个很好理解,虽然树形结构可以有很深的层次,但是太深就意味着难以维护,所以要尽量保持树形结构的扁平化。
组合 Reducer
我们在之前提到过在 redux 中有提供一个 combineReducers 的函数,它可以把多个 reducer 函数合成为一个 reducer 函数。
combineReducers函数接受一个对象作为参数,参数对象的每个字段名对应了 State 状态上的字段名,每一个字段的值都是一个 reducer 函数。
combineReducers函数返回一个新的 reducer 函数,当这个新的 reducer 函数被执行时,会把传入的 state 参数对象拆开处理,然后把拆开的 reducer 进行调用,并将调用的返回结果合并成一个新的 state,作为整体 reducer 函数的返回结果。
View 视图开发注意点
- 对于视图 View 来说,当一个包含 ref 属性的组件完成装载(mount)过程的时候,会看一看 ref 属性是不是一个函数,如果是,就会调用这个函数,参数就是这个组件代表的 DOM 元素。
- JSX 中可以使用任何形式的 JS 表达式,只要 JS 表达式出现在大括号之间。但是这里只能是 JS 表达式。
- 对于动态数量的子组件,每个子组件都必须要带上一个 key 属性,而且这个 key 属性的值一定钥匙能够唯一标识这个子组件的值
React 组件的性能优化
我们应该忘记忽略很小的性能优化,可以说 97% 的情况下,过早的优化是万恶之源,而我们应该关心对性能影响最关键的那另外 3% 的代码。——高德纳
不要过早优化说的是不要过早去处理那些无法量化的优化地方,也不要将性能优化的精力浪费在对整体性能提高不大的代码上。对那些明显影响系统和整体性能的问题地方,优化并不嫌早。
开发者永远要考虑到极端情况。
React 在更新节点时,会有一个找不同的过程,这个过程我们叫它调和(Reconciliation)。
按照计算机科学目前的算法研究结果,对于两个N个节点的树形结构的对比算法,时间复杂度为O(n^3)。打个比方,假如两个树形结构上各有100个节点,那么找出两个树形结构差别的操作,需要 100 x 100 x 100次操作,也就是一百万次,那如果各有1000个节点,将会有1亿次的操作量,这在浏览器中是不可想象的,所以 React 不可能采用这种算法进行 DOM 更新。
React 实际上采用的算法需要的时间复杂度是O(n),因为对比两个树形怎么着都要对比两个树形上的节点,所以也不太可能有比时间复杂度更低的算法了。
其实 React 的 Reconciliation 算法并不复杂,当 React 要对比两个虚拟DOM的属性结构的时候,从根节点开始递归往下比对,在树形结构上,每个节点都可以看作一个这个节点以下部分子树的根节点。所以其实这个对比算法可以从虚拟DOM上任何一个节点开始执行。
React 首先检查两个树形的根节点的类型是否相同,根据相同或者不同有不同的处理方式。
1. 节点类型不同的情况
如果树形结构根节点类型不同,那就意味着改动很大了。我们可以直接认为原来那个树形结构已经没用,可以扔掉了。此时需要重新构建新的 DOM 树,原有的树形上的 React 组件会经历卸载的生命周期。
2. 节点类型相同的情况
我们先来了解一下节点的类型,一般分为两类:一类是 DOM 元素类型,对应的就是 HTML 直接支持的元素类型,比如 div、span 和 p;另一类是 React 组件,也就是利用 React 定制的类型。
Key 的用法
React 不会使用一个 O(n^2) 时间复杂度的算法去找出前后两列子组件的差别,默认情况下,在 React 的眼里,确定每一个组件在组件序列中的唯一标识就是它的位置,所以它也完全不懂哪些子组件实际上并没有改变,为了让 React 更加聪明,就需要开发者提供一点帮助。
在 React 中给每个组件唯一标识的属性就是 key 属性,我们可以把它看成一个身份证号码。
使用 reselect 提高数据获取性能
reselect 库的工作原理:只要相关状态没有改变,那就直接使用上一次的缓存结果。
reselect 认为一个选择器的工作可以分为两个部分,把一个计算过程分为两个步骤:
- 从输入参数 state 抽取第一层结果,将这第一层结果和之前抽取的第一层结果做比较,如果发现完全相同,就没有必要进行第二部分运算了,选择器直接把之前第二部分的运算结果返回就可以了。注意,这一部分做的比较,就是使用 JS 的三等运算符进行比较,如果第一层结果是对象的话,只有是同一个对象才会被认为是相同。这一步的运算要尽量简单快捷
- 根据第一层结果计算出选择器需要返回的最终结果。
范式化状态树
所谓范式化,就是遵照关系型数据库的设计原则,减少冗余数据。
反范式化是利用数据冗余来换取读写效率,因为关系型数据库的强项虽然是保持一致,但是应用需要的数据形式往往是多个表 join 之后的结果,而 join 的过程往往耗时而且在分布式系统中难以应用。但是反范式化数据结构的特点就是读取容易,修改比较麻烦。
高阶组件
定义高阶组件的意义何在呢?
- 首先,重用代码;
- 其次,修改现有 React 组件的行为;
而根据返回的新组件和传入组件参数的关系,高阶组件的实现方式可以分为两大类:
- 代理方式的高阶组件
- 继承方式的高阶组件
代理方式的高阶组件
特点是返回的新组件类直接继承自
React.Component类。新组件扮演的角色是传入参数组件的一个代理,在新组建的 render 函数中,把被包裹组件渲染出来,除了高阶组件自己要做的工作,其余功能全都转手给了被包裹的组件。
代理方式的高阶组件,可以应用在下列场景中:
- 操作 prop
- 访问 ref
- 抽取状态
- 包装组件
继承方式的高阶组件
继承方式的高阶组件采用继承关系关联作为参数的组件和返回的组件,假如传入的组件参数是
WrappedComponent,那么返回的组件就直接继承自WrappedComponent。
function ExtendsComponent(WrappedComponent) {
return class NewComponent extends WrappedComponent {
render() {
const { user, ..otherProps } = this.props;
this.props = otherProps;
return super.render();
}
}
}
代理方式和继承方式最大的区别,就是使用被包裹组件的方式。
在代理方式下 WrappedComponent 经历了一个完整的生命周期,但在继承方式下 super.render 只是一个生命周期中的一个函数而已;在代理方式下产生的新组件和参数组件是两个不同的组件,一次渲染,两个组件都要经历各自的生命周期,在继承方式下两者合二为一,只有一个生命周期。
优先考虑组件,然后才考虑继承
以函数为子组件
以函数为子组件的模式非常适合于制作动画,类似可以决定动画每一帧什么时间绘制,绘制的时候是什么样的数据,作为子组件的函数只要专注于使用参数来渲染就可以了。
虽然这种模式可以让代码非常灵活,但是它的缺点也很明显,那就是难以做性能优化。
代理访问 API
因为对于浏览器而言,跨域访问 API 会被限制,而服务器端则没有这种限制,所以我们一般会起一个轻量服务做代理工作,从而实现对跨域资源的访问。
我们也可以在项目根目录的 package.json 中添加如下一行:
"proxy": "要代理的 API 地址"
这个配置会告诉当前应用,当接收到的不是本地资源的 HTTP 请求时,这个 HTTP 请求的协议和域名部分就会替换为我们设置的部分,然后转发出去,并将收到的结果返回给浏览器,也实现了代理功能。
我们需要注意的是对于任何输入和输出操作——都不要相信任何返回结果。
Redux 中间件
书中主要介绍了 redux-thunk 中间件,thunk 是一个计算机编程的术语,表示辅助调用另一个子程序的子程序。
按照 redux-thunk 的想法,在 Redux 的单向数据流中,在 action 对象被 reducer 函数处理之前,是插入异步功能的时机。
在 Redux 架构下,一个 action 对象通过 store.dispatch 派发,在调用 reducer 函数之前,会先经过一个中间件环节,这就是产生异步操作的机会,实际上 redux-thunk 提供的就是一个 Redux 中间件,我们需要在创建 Store 时用上这个中间件。
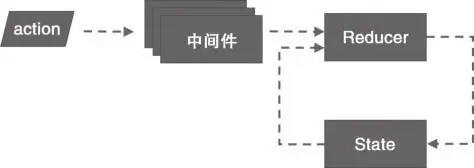
不同的中间件之间是可以相互组合使用的,这是因为 Redux 要求所有中间件必须提供统一的接口,每个中间件的实现逻辑都不一样,但是只有遵守统一的接口才能够和 Redux 和其他中间件对话。
在 Redux 框架中,中间件处理的是 action 对象,而派发 action 对象的就是 Store 上的 dispatch 函数。action 对象最终会进入到 reducer 中,而在这之前,它其实会经历中间件的管道。
对于中间件来说,必须要将其定义成一个函数,返回一个接受 next 参数的函数,而这个接受 next 参数的函数又返回一个接受 action 参数的函数。next 参数本身也是一个函数,中间件调用这个 next 函数通知 Redux 自己的处理功能已经结束,可以执行下一个工作了。
我们来看一个什么都不做的中间件长啥样:
function doNothingMiddleware({ dispatch, getState }) {
return function (next) {
return function (action) {
return next(action)
}
}
}
每个中间件必须是独立存在的,但是要考虑到其他中间件的存在。
所谓独立存在,指的是中间件不依赖于和其他中间件的顺序,也就是不应该要求其他中间件必须出现在它前面或者后面,否则事情会复杂化。
对于异步动作的中间件来说,等于是要吞噬掉某些类型的 action 对象,这样的 action 对象不会交还给管道。中间件会异步产生新的 action 对象,这时候不能通过 next 函数将 action 对象还给管道,因为 next 不会让 action 被所有中间件处理,而是从当前中间件之后的管道位置开始被处理。
一个中间件如果产生了新的 action 对象,正确的方式是使用 dispatch 函数派发,而不是使用 next 函数。
中间件用于扩展 dispatch 函数的功能,多个中间件实际构成了一个处理 action 对象的管道,action 对象被这个管道中所有中间件依次处理过之后,才有机会被 reducer 处理。
Redux 和服务器通信
当我们想要让 Redux 帮忙处理一个异步操作的时候,代码一样也要派发一个 action 对象,毕竟 Redux 单向数据流是由 action 对象驱动的。但是这个引发异步操作的 action 对象比较特殊,我们叫它异步 action 对象。
之前的 action 构造函数返回的都是一个普通的对象,而异步 action 对象则不再是一个普通的 JS 对象那么简单,它是一个函数。
我们来看一个例子:
const incrementAsync = () => {
return (dispatch) => {
setTimeout(() => {
dispatch(increment())
}, 1000)
}
}
这里异步 action 函数 incrementAsync 返回的是一个新的函数,这样一个函数被 dispatch 派发之后,会被 redux-thunk 中间件执行,于是 setTimeout 函数就会发生作用,在 1S 之后利用参数 disptach 函数派发出同步 action 构造函数 increment 的执行结果。
这就是异步 action 的工作机理,这个例子虽然简单,但是我们可以知道,异步 action 最终还是要产生同步 action 派发才能对 Redux 系统产生影响。
action 对象函数中完全可以通过 fetch 发起一个对服务器的异步请求,当得到服务器结果之后,通过参数 dispatch,把成功或者失败的结果当作 action 对象再派发出去。这时派发的就是普通的 action 对象了,也不会被 redux-thunk 截获,而是直接被派发到 reducer,最终驱动 Store 上的状态改变。
一般来说,异步 action 构造函数的代码基本上都是如下的套路:
export const sampleAsyncAction = () => {
return (dispatch, getState) => {
// 在这个函数里可以调用异步函数,自行决定在合适的时机通过 disptach 参数派发出新的 action 对象
}
}
单元测试
测试种类
- 从人工操作还是写代码来操作的角度,可以分为手工测试和自动化测试;
- 从是否需要考虑系统的内部设计角度,可以分为白盒测试和黑盒测试
- 从测试对象的级别,可以分为单元测试、集成测试和端到端测试
- 从测试验证的系统特性,又可以分为功能测试、性能测试和压力测试
我们主要看其中的单元测试。
单元测试是一种自动化测试,测试代码和被测的对象非常相关。单元测试代码一般都由编写对应功能代码的开发者来编写,开发者提交的单元测试代码应该保持一定的覆盖率,而且必须永远能够运行通过。可以说,单元测试是保证代码质量的第一道防线。
而说到单元测试,就不得不说测试驱动开发(Test Driven Developement, TDD)。对于TDD,业内人士对其褒贬不一,虽然它能保证其他开发者不会因为失误破坏原有的功能,但是也会导致增加自身的工作量,毕竟测试代码的编写会是功能代码的好几倍。比如为了写一个单元测试要写太多的 Mock,涉及复杂的流程难以全部条件分支。
要克服单元测试太难写的问题,就需要架构能把程序拆分成足够小到方便测试的部分,只要每个小的部分被验证能够正确地各司其职,组合起来能够完成整体功能,那么开发者编写的单元测试就可以专注于测试各个小的部分就行,这就是更高的可测试性。
测试框架
前端测试框架,常见的有以下几类:
- Mocha:它没有断言库,所以往往需要配合 Chai 断言库来使用
- Jest:React 框架本家 Facebook 出品的 Jest,自带了断言的功能,且。CRA 创建应用的时候会自带 Jest 库。
在用 CRA 创建项目之后,执行 npm run test 命令,启动单元测试,此时会进入待命状态:
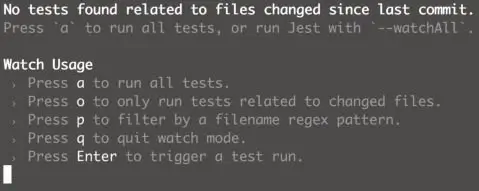
在待命状态下,任何对相关代码的修改,都会触发单元测试的运行,而且 Jest 很智能,只运行修改代码影响的单元测试。同时也提供了强行运行所有单元测试代码、选择只运行满足过滤条件的单元测试用例等高级功能。
Jest 会自动在当前目录下寻找满足下列任一条件的 JS 文件作为单元测试代码来执行。
- 文件名以
.test.js为后缀的代码文件 - 存于
__test__目录下的代码文件
一种方式,是在项目的根目录上创建一个名为 test 的目录,和存放功能代码的 src 目录并列,在 test 目录下建立和 src 对应子目录结构,每个单元测试文件都以 .test.js 后缀,就能够被 Jest 找到。这种方法可以保持功能代码 src 目录的整洁,缺点就是单元测试中引用功能代码的路径会比较长。
测试代码组织
单元测试代码的最小单位是测试用例(test case),每一个测试用例考验的是被测试对象在某一个特定场景下是否有正确的行为。在 Jest 框架下,每个测试用例用一个 it 函数代表,it 函数的第一个参数是一个字符串,代表的就是测试用例名称,第二个参数是一个函数,包含的就是实际的测试用例过程。
而比较好的测试用例名称遵循这样的模式:(它)在什么样的情况下是什么行为。应该尽量在 it 函数的第一个参数重使用这样有意义的字符串。
那如何组织多个 it 函数实例,也就是测试套件(test suite)的构建呢?
一个测试套件由测试用例和其他测试套件组成,很明显,测试套件可以嵌套使用,于是测试套件和测试用例形成了一个树形的组织结构。当执行某个测试套件的时候,按照从上到下从外到内的顺序执行所有测试用例。
单元测试的基本套路如下:
- 预设参数
- 调用纯函数
- 用 expect 验证纯函数的返回结果
在 Redux 中做单元测试时,dispatch 函数最好不要做实际的派发动作,只要能够把被派发的对象记录下来,留在验证阶段读取就可以了。
动画
CSS3方式
CSS3 Transition 对一个动画规则的定义是基于时间和速度曲线(Speed Curve)的规则。换句话来说,就是 CSS3 的动画过程要描述成“在什么时间范围内,以什么样的运动节奏完成动画”。
脚本方式
相对于 CSS3 方式,脚本方式最大的好处就是更强的灵活度。但是确定也很明显,动画过程通过 JS 实现,不是浏览器原生支持,小号的计算资源更多。如果处理不当,还有可能出现卡顿滞后的现象。
现在流行的动画脚本库,一般都以16毫秒作为一个时间间隔来进行动画渲染。那么为什么要选择16毫秒呢?
因为每秒渲染60帧(也叫 60 fps,Frame Per Second)会给用户带来足够流畅的视觉体验,一秒有1000毫秒,1000/60约等于16,也就是说,如果我们做到每秒16毫秒去渲染一次画面,就能够达到比较流畅的动画效果。
但实际上,因为一帧的渲染需要占用网页线程的32毫秒,这会导致类似 setInterval 定时器根本无法以16毫秒间隔调用渲染函数,这就产生了明显的动画滞后感,原本一秒钟完成的动画现在要花2S完成,所以类似定时器这种方式不适合复杂动画。因为它们并不能保证在指定时间间隔或者延迟的情况下准时调用指定函数。
这里需要换一个思路,当指定函数调用的时候,根据逝去的时间计算当前这一帧应该显示什么,这样即使因为浏览器渲染主线程忙碌导致一帧渲染时间超过16毫秒,在后续帧渲染时至少内容不会因此滞后,即使达不到60fps的效果,也能保证动画在指定时间内完成。
我们可以实现一个 raf 函数,即 request animation frame:
let lastTimeStamp = new Date().getTime();
function raf(fn) {
const currentTimeStamp = new Date().getTime();
let delay = Math.max(0, 16-(currentTimeStamp - lastTimeStamp));
const handle = setTimeout(() => {
fn(currentTimeStamp)
}, delay);
lastTimeStamp = currentTimeStamp;
return handle;
}
同构
一个 React 组件或者说功能组件既能够在浏览器端渲染也可以在服务端渲染产生 HTML,这种方式叫做同构。
传统上,一个浏览器端渲染的方案,一般要包含以下几个部分:
- 一个应用框架,包含路由和应用结构功能
- 一个模板库
- 服务器端的 API 支持
但是我们说完全的浏览器端渲染很有市场,但是也有它的局限性:最主要的就是首页性能。
为了便于量化网页性能,我们定义了两个指标:
- TTFP(Time To First Paint):指的是从网页 HTTP 请求发出,到用户可以看到第一个有意义的内容渲染出来的时间差;
- TTI(Time To Interactive):指的是从网页 HTTP 请求发出,到用户可以对网页内容进行交互的时间。
对于一个服务端渲染来说,因为获取 HTTP 请求就会返回有内容的 HTML,所以在一个 HTTP 的周期之后就会提供给浏览器有意义的内容,所以首次渲染时间 TTFP 会优于完全依赖于浏览器端渲染的页面。
而除了更短的 HTTP,服务端渲染还有一个好处就是利于搜索引擎优化,也就是 SEO。
上面的性能对比当然只是理论上的分析,实际中,采用服务器端是否获得更好的 TTFP 有多方面因素。
- 首先,服务器端获取数据快还是浏览器端获取数据快?大多数情况下,在网页服务器上获取数据的确更快,开发者只需要确认这一点就行
- 其次,服务器端产生的 HTML 过大是否会影响性能?这是必然的,特定于React应用,服务器端渲染需要在网页中包含“脱水数据”,除了HTML之外还要包含输入给React重新绘制的数据,这样导致页面的大小比最传统的服务器端渲染产生的页面还要大,更要考虑页面大小对性能的影响。
- 最后,服务器端渲染的运算消耗是否是服务器能够承担得起的?对于浏览器端渲染来说,服务器只提供静态资源,还有 API,这样一来,服务器基本没啥压力;而如果使用服务器渲染,那么页面请求都要产生 HTML 页面,这样服务器的运算压力也就增大了。
React 服务器端渲染 HTML
如果要应用 React 服务器端渲染,一样要利用 React 浏览器渲染。过程如下:
服务器端渲染产生的 React 组件 HTML 被下载到浏览器网页之中,浏览器网页需要使用 render 函数重新渲染一遍 React 组件。这个过程看起来会比较浪费,不过在浏览器端的 render 函数之前,用户就已经看见服务器端渲染的结果了,所以用户感知的性能提高了。
实现同构很重要的一条,就是一定要保证服务器端和浏览器端渲染的结果要一模一样。如果服务器端渲染和浏览器端渲染产生的内容不一样,用户会先看到服务端渲染的内容,然后浏览器渲染会重新渲染内容,用户就会看到一次闪烁,这样的用户体验很不好。
为了让两端数据一致,就要涉及脱水和注水的概念。
React 同构中的这两个概念,和三体人的奇异能力很相似。
脱水:服务器端渲染产出了 HTML,但是在交给浏览器的网页中不光要有 HTML,还需要有脱水数据,也就是服务器渲染过程中给 React 组件的输入数据。
注水:接脱水的概念,当浏览器渲染时,可以直接根据脱水数据来渲染 React 组件,这个过程叫做注水。
脱水数据的传递方式一般是在网页中内嵌一段 JS,内容就是把传递给 React 组件的数据赋值给某个变量,这样浏览器就可以直接通过这个变量获取脱水数据。
End
笔记记录结束,这本书比较早了,里面的内容主要还是类组件。但是无可否认的是,里面的干货很多,从纯编程思维的角度去讲述了某些框架为什么这么设计,好处是什么,坏处是什么,如何取舍,怎么开放更合理,为什么?
很多都是从实际出发来讲解,让读者了解原理,而不是怎么去用。